
Its Science Fair time again. Today we were experimenting with different variations of a very simple reinforcement learning algorithm (Q learning) by varying the available actions and the trade-off between exploration (taking a random action) vs. exploitation (taking the best learned action). Our bearded dragon was happy to help, but was a bit leery of the whirring Lego Mindstorms EV3 robot.
The robot currently uses one touch sensor (just behind the pivoting bumper) to sense when it hits something and an infrared sensor to detect distance. The infrared sensor is not very precise. Sometimes it reports that it is close to an object when it is actually far away and vice versa, even when the sensor and the obstacle are not moving. To correct for this we ordered an ultrasonic sensor that is supposed to be more precise and more accurate.
The robot learns by constantly updating a table of expected long term reward values indexed by its sensor data and the possible actions it can take. If it moves forward it gets 1 point, a forward turn to the right or left gets .5 points, hitting an obstacle gets -5 points. Everything else scores 0.
Within 1000 trials it can learn to avoid obstacles, but it clearly isn't approaching optimal behavior. My daughter's experiment will likely be to explore a variety of parameters to see how they affect the quality of the learned behavior, measure as the total reward over a number of action steps (probably 1500 to 2000) and the average reward over the last 100 steps. We are not sure of the exact experiment yet. She keeps coming up with different ideas to try.
The learning algorithm is designed to run in one of two ways: directly on the robot or on a laptop using remote procedure calls. Instead of using Lego's built-in operating system on the robot, we installed a version of Linux designed for the Lego EV3 robot (ev3dev) and wrote the code in Python. ev3dev is really easy to install, because instead of replacing the Lego OS, it runs off a micro SD card that you pop into the EV3. With the card inserted, the EV3 will automatically boot up into Debian Linux, ready to run Python with a package that makes it easy to use all of the motors and sensors in the EV3.
Of course, like all things Linux, it took dad (me!) hours to get this all set up, what with all the different versions of each package, the need to use a remote shell over Bluetooth to install packages on the robot, etc. But now that it is all done it works quite well.
Here is an example of the lookup table (called the Q table) that the robot learned after 1000 steps with exploratory behavior slowly decreasing from a 100% chance of making a random action in the first step to just under a 10% chance by step 1000.
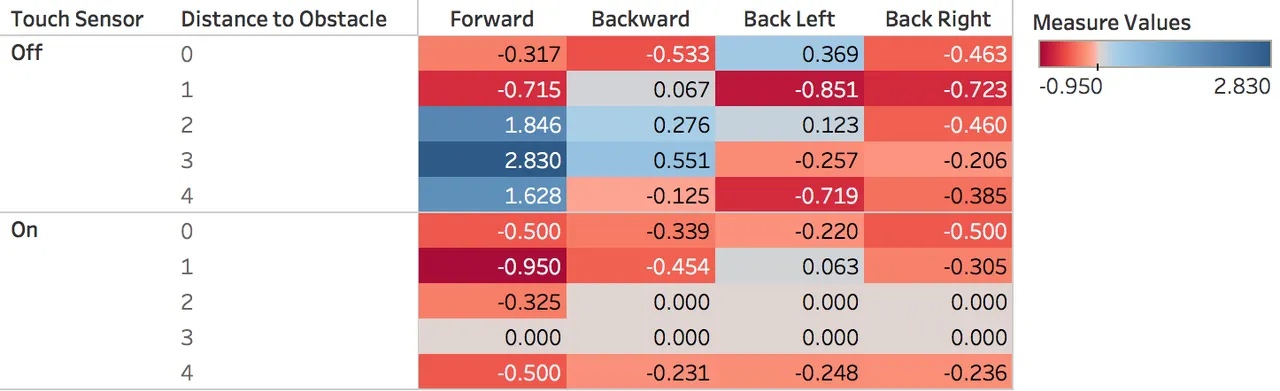
Recall that the robot's view of the world is just the state of its sensors: whether the touch sensor is on (hitting something) or off, and the distance reported by the infrared (IR) sensor. The IR sensor reports distance from 0 to 100, with 0 being closest to an object and 100 at around 70 cm away. I rescaled this to 5 distances (0 to 4), because otherwise the robot would have to learn a much bigger table, which would require many, many more trials.
The table tells the robot its expected long-term reward of taking each action in each possible state. The robot wants to maximize its reward, so actions with bigger numbers (shown in blue) are better. To find the best action, the robot finds the row that matches its current sensor readings and then finds the action in that row with the highest value. For example, if the touch sensor is off, and the distance to an obstacle is 3, the table tells the robot that moving Forward is the best choice with an expected reward of 2.83. All other actions in that state have lower expected values.
The table also shows limitations with the robot's sensors. If you look at the touch sensor On part of the table, you'll see that there are values where the IR sensor indicated it was 4 units from an obstacle; however, if it was that far, the touch sensor shouldn't be on. This is a limitation of the the robots ability to sense its environment. If the robot is moving along a wall, but is slightly pointed toward the wall, its front bumper can catch the wall and trigger the touch sensor, while the IR sensor is still pointing much further down the wall and measuring a much larger distance. Soon we plan to test replacing the IR sensor with the more precise and accurate Lego Ultrasonic Sensor.
You can also see several cells with 0.000, meaning the robot never took an action in that part of the state space. In fact, since the row for Touch = On and Distance = 3 is all 0's, it means that the robot was never in those states.
Overall, it's very exciting to see such a simple robot learn by doing. Although the Q learning algorithm is fairly old, it is still surprisingly useful. DeepMind's Atari game playing used a much more advanced version of this same algorithm (called Deep Q Network) to learn to play a large number of different Atari 2600 games given only the screen pixels and score as input.
This is a semester long project, so I'll be posting more updates as we move through the project.
Todd
To support this post please upvote, follow 
Presearch: Earn Cryptocurrency By Searching the Internet
Honeyminer: Start mining bitcoin in 1 minute
Proud member of


